The Fatal Flaw of Patterns: ECB vs CBC Mode in Cryptography
Before diving into the deep statistical analysis of cryptographic vulnerabilities, we must understand a fundamental mathematical phenomenon known as the Strict Avalanche Criterion (SAC). In a mathematically perfect cryptographic system, flipping just a single bit of the input plaintext must statistically flip exactly 50% of the output ciphertext bits, creating a massive, unpredictable cascading effect.
However, achieving this theoretical perfection across gigabytes of structured data is impossible if you choose the wrong encryption architecture. When evaluating the security posture of ECB vs CBC mode, the absolute core difference lies in how this avalanche effect is handled: does the system isolate the chaos within a single microscopic 128-bit block, or does it mathematically force the chaos to diffuse and propagate through the entire dataset?
Cryptosystems fail not because attackers break the mathematics of the cipher, but because engineers fail to understand the flow of data. If you have mastered our previous modules on Shannon Entropy and the Birthday Paradox Bound, you know that cryptography requires absolute, unguessable randomness.
A modern cipher like AES (Advanced Encryption Standard) is computationally unbreakable. But AES is a block cipher—it can only encrypt fixed-size blocks (128 bits for AES) of data at a time. To encrypt a large file, such as a database table or an image, you must define a mathematical protocol to process these sequential blocks.
These protocols are called block cipher modes of operation. Choosing the wrong mode leads to catastrophic information leakage, even if your AES key is millions of bits long. In this definitive guide, we will analyze the mathematics of statistical cryptanalysis, prove why the standard Electronic Codebook (ECB) mode is fatally flawed, and demonstrate how Cipher Block Chaining (CBC) with robust initialization vector cryptography creates impenetrable statistical “noise.”
1. The Math of Predictability: Zipf’s Law and Frequency Analysis
The core vulnerability that forces the use of complex encryption modes is the inherent structure of human data. Computers do not produce random bytes; they produce structured information that adheres to strict statistical laws. Natural languages, relational databases, and even structured application logs exhibit clear patterns.
Zipf’s Law and Natural Language
The primary weapon of statistical cryptanalysis is frequency analysis. Consider Zipf’s Law, which dictates that in any large natural language corpus, the frequency of any word is inversely proportional to its rank in the frequency table. For example, in English, the word “the” accounts for roughly 7% of all words, “of” accounts for 3.5%, and “and” accounts for 2.8%.
This distribution means that even a simple substitution cipher can be broken in seconds by a modern CPU, simply by mapping the most frequent ciphertext letters to “t,” “h,” and “e.” A block cipher must destroy these underlying structures.
Variance and Standard Deviation
To mathematically measure how effective a block cipher mode is, we analyze the resulting ciphertext using variance ($\sigma^2$) and standard deviation ($\sigma$). In a perfectly random sequence (ideal ciphertext), the variance of byte values should be high, indicating a uniform distribution where no byte value appears more often than any other.
If the standard deviation is low, it means the byte values cluster tightly around the mean, which is a key indicator of underlying structure. **Statistical cryptanalysis** utilizes Chi-squared ($\chi^2$) tests to prove that a ciphertext’s byte distribution deviates from a theoretical uniform distribution, signaling an attack vector.
2. The Problem: Block Cipher Modes of Operation and Data Structure
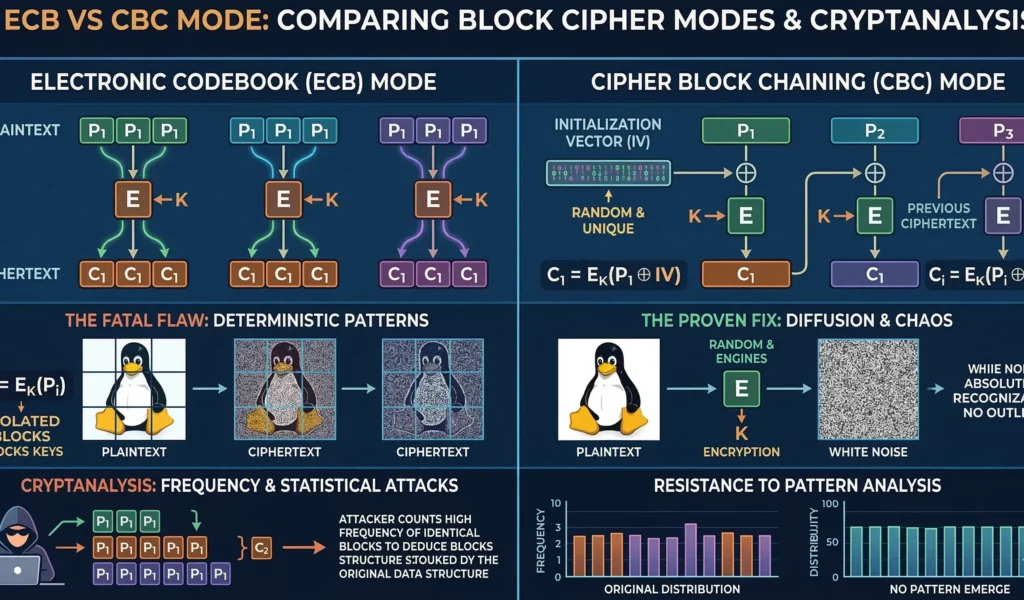
When security architects evaluate block cipher modes of operation, they often refer to the strict standards defined by global cybersecurity bodies. According to the official NIST Special Publication 800-38A, which formally standardizes these cryptographic methods, choosing the right mode is just as critical as the encryption cipher itself. The simplest, yet most dangerous of these block cipher modes of operation is the Electronic Codebook (ECB). In ECB mode, every plaintext block ($P_i$) is encrypted with the same key ($K$) to produce a ciphertext block ($C_i$), completely independent of all other blocks.
$$C_i = E_K(P_i)$$
$$P_i = D_K(C_i)$$
This approach works for a single 128-bit block. However, if you have a 1 MB file, you may have thousands of identical blocks. A common database log file might have 1,000 blocks containing the exact same ASCII string: "USER AUTH SUCCESS".
3. The ECB Disaster: Why Naive Hashing is a Catastrophe
The fatal flaw of ECB mode is its determinism. If the plaintext block is the same, and the key is the same, the ciphertext block is always the same. **Statistical cryptanalysis** does not need to guess the key; it only needs to observe that a specific 128-bit pattern of ciphertext appears 1,000 times, while another pattern appears only 5 times.
Because the output of ECB is strictly deterministic, a hacker performing statistical cryptanalysis can simply count the frequency of recurring encrypted blocks. If a specific 128-bit block appears 50 times in the ciphertext, statistical cryptanalysis dictates that the corresponding plaintext block also appeared exactly 50 times. This allows attackers to map out and reconstruct the underlying structure of the entire database without ever breaking the AES encryption key itself.
Visualizing the Failure: ECB vs CBC Mode Patterns
This statistical leakage can be visualized dramatically. Consider the iconic example of “Tux the Penguin.” The image on the left is the unencrypted plaintext. The middle image shows the same data encrypted using AES in ECB mode. The image on the right is encrypted using AES in CBC mode.
As you can see, the ECB image is a cryptographic catastrophe. Although the byte values are shifted (making it look “noisy”), the underlying statistical patterns of the image—the outlines of the penguin’s body, eyes, and belly—remain perfectly preserved.
A machine learning algorithm could reconstruct the original image with high accuracy, even without knowing the AES key. When we analyze **ECB vs CBC mode**, ECB fails the most fundamental goal of cryptography: confidentiality.
4. Diffusion and Confusion: Mastering CBC Mode and Data Dependence
To solve the fatal flaw of ECB determinism, we need a mode that introduces *data dependence*. We must ensure that a change in any single bit of the plaintext propagates randomness throughout all subsequent blocks. This is precisely what the Cipher Block Chaining (CBC) mode achieves.
In CBC mode, before a plaintext block ($P_i$) is encrypted, it is combined with the ciphertext block from the *previous* operation ($C_{i-1}$) using the XOR ($\oplus$) operator. The output of this XOR is then fed into the AES encryption function.
$$C_i = E_K(P_i \oplus C_{i-1})$$
$$P_i = D_K(C_i) \oplus C_{i-1}$$
This simple XOR operation creates a cascading effect of diffusion. The first byte of the second block is now dependent on the last byte of the first block, and the first byte of the third block is dependent on everything that came before it. This diffusion successfully shatters the visual and statistical patterns that **ECB vs CBC mode** visualizes.
5. The Catalyst of Chaos: Initialization Vector Cryptography
CBC mode appears mathematically sound, but there is still one remaining flaw: what happens at the very first block ($P_1$)? Because there is no $C_0$ (previous ciphertext) to XOR against, the first block is vulnerable. If a database is full of rows that all begin with the exact same data structure (like an ASCII header `ID_NUMBER:`), the first block of all encrypted database rows will still be deterministic and reveal patterns.
This is where initialization vector cryptography becomes critical. The solution is to introduce a unique, unpredictable, randomized start point for the chaining process: the Initialization Vector (IV).
For the very first block, the operation is:
$$C_1 = E_K(P_1 \oplus \text{IV})$$
The ultimate goal of initialization vector cryptography is to ensure that identical messages never encrypt to the same ciphertext. When evaluating the security posture of ECB vs CBC mode, the presence of a randomized IV is the defining architectural factor that stops frequency analysis dead in its tracks. Proper initialization vector cryptography acts as the unpredictable mathematical seed that guarantees perfect forward diffusion across the entire dataset, completely mitigating the vulnerabilities of ECB.
The IV serves as a unique catalyst that guarantees that even if you encrypt the exact same plaintext table twice using the exact same AES key, the first block (and all subsequent blocks) will be completely unique, random, and statistically unpredictable.
- **IV Requirement 1: Unique (A Nonce):** The IV must *never* be reused with the same key.
- **IV Requirement 2: Unpredictable:** The IV should be generated using a Cryptographically Secure PRNG (as discussed in Module 1) to prevent attackers from predicting and reversing the first XOR operation.
- **IV Requirement 3: Does Not Need to Be Secret:** The IV is typically transmitted unencrypted (often appended to the ciphertext). This is acceptable because, while the attacker knows the IV, they cannot decrypt the output of the XOR without the AES secret key $K$.
6. Performance Trade-offs and The Padding Oracle Threat
When enterprise architects finalize their decision regarding ECB vs CBC mode, they must weigh the mathematical security against pure computational throughput. Because Electronic Codebook (ECB) encrypts every 128-bit block completely independently, it allows for massive parallel processing.
A modern multi-core CPU can encrypt a 10 GB file in ECB mode almost instantly by dividing the blocks across all available threads. However, as we have proven, this speed comes at the unacceptable cost of total vulnerability to statistical cryptanalysis.
Conversely, Cipher Block Chaining (CBC) is strictly sequential. You cannot mathematically compute the ciphertext of block $C_2$ until block $C_1$ has been fully encrypted and XORed. This creates a severe computational bottleneck in high-throughput environments.
Furthermore, while the implementation of robust initialization vector cryptography perfectly protects the ciphertext against passive observation and pattern matching, it does not protect against active manipulation. One of the most devastating exploits targeting legacy block cipher modes of operation is the Padding Oracle Attack.
Because block ciphers require data to be perfectly aligned to 128-bit boundaries, any missing space is filled with “padding” bytes. In a Padding Oracle Attack, a hacker intercepts the CBC ciphertext and slowly alters the final bytes. They then send this corrupted data back to the server and observe the error messages.
By analyzing how the server reacts to invalid padding, the attacker can mathematically reverse-engineer the XOR operations and decrypt the entire payload byte-by-byte, completely bypassing the protection of the initial IV. This proves that while understanding ECB vs CBC mode is essential, modern systems must ultimately move towards Authenticated Encryption (like AES-GCM) to ensure both confidentiality and data integrity.
7. Conclusion: Diffusion Over Determinism
The comparison of **ECB vs CBC mode** teaches a fundamental lesson in cybersecurity architecture: complexity must be introduced precisely where deterministic mathematical structures create vulnerabilities. ECB mode is deterministic and leaves visual and statistical signatures, failing to satisfy the requirements of perfect secrecy.
Through the correct implementation of a cryptographically secure pseudo-random number generator, a cascading diffusion layer (Cipher Block Chaining), and robust **initialization vector cryptography**, security architects can convert highly structured data into perfect statistical noise. Mastering these block cipher modes of operation is the difference between building a secure database and building a vulnerable archive of pattern-filled data leaks.
In our next module, we will explore advanced symmetric cryptography concepts, including Galois/Counter Mode (GCM), which combines the speed of block ciphers with integrity validation, creating authenticated encryption that prevents attackers from modifying your data.
Bądź na bieżąco!
Zapisz się, aby nie przegapić nowości na Review Space.
Join Our Newsletter
No spam. Unsubscribe anytime.